Skip-gram模型(1)
Table of Contents
简介 #
Skip-gram1属于Word2Vec的一种,给定input,预测上下文,而CBOW(见补充)是通过上下文来预测input。
Word2Vec模型分为两个步骤2:
- 建立模型,这类方法与自编码模型有点像,建模不是最终目的;
- 通过模型获取嵌入词向量。
模型细节 #
整体框架图
输入层 #
词不能直接输入神经网络模型,比如训练样本中有10000个不同的词,将某个词“我”或者“我们”进行one-hot编码,形成10000维的向量,其中“我”的地方为1,其他均为0。对于Skip-gram输入单个词向量,输出就是这个词附近的词组成的向量。
模型输入输出均为10000维度向量$\{0,1\}^{10000}$
隐含层 #
假如想用300个特征来表征词,那么隐含层单个神经元权重为[10000, 1],300个神经元为[10000, 300]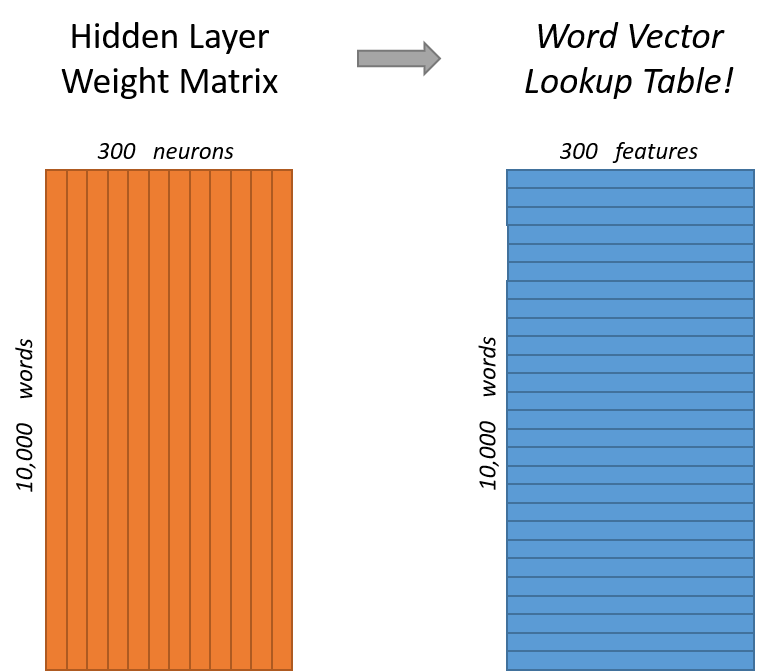
上图可以理解为输入经过隐含层作用刚好得到单词的表征。输入和隐含层两部分可以进行词嵌入即embedding。
输出层 #
模型输出为10000维度向量,要达到这样的输出层为10000个神经元,并且这些神经元输出和为1,使用softmax函数来达到这种效果。以下两个等式展示一个词向量在神经网络中的前向传播。
$$ \begin{bmatrix} 1 & 10000 \end{bmatrix} \times \begin{bmatrix} 10000 & 300 \end{bmatrix} = \begin{bmatrix} 1 & 300 \end{bmatrix} \ $$
$$ \begin{bmatrix} 1 & 300 \end{bmatrix} \times \begin{bmatrix} 300 & 10000 \end{bmatrix} = \begin{bmatrix} 1 & 10000 \end{bmatrix} \ $$
补充 #
skip-gram名字由来3:
首先n-gram是一系列连续的词(tokens),而skip-gram,或者skip-n-gram,skip的是token之间的gap,jumps over the是一个3-gram,那么(jumps, the)刚好skip了一个gram (over)。
什么是Softmax?4
Softmax从字面上来说,可以分成soft和max两个部分。max故名思议就是最大值的意思。Softmax的核心在于soft,而soft有软的含义,与之相对的是hard硬。很多场景中需要我们找出数组所有元素中值最大的元素,实质上都是求的hardmax。hardmax最大的特点就是只选出其中一个最大的值,即非黑即白。Softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。经过使用指数形式的Softmax函数能够将差距大的数值距离拉的更大。
CBOW是什么?
Continuous Bag of Word Model连续词带模型,通过上下文来预测中间的词