医学人工智能周刊6|模态无关的学习方法在医学影像以及生理信号中的评测
Table of Contents
摘要 #
目的:建立基准测试BenchMD,用于测试模型无关的方法包括架构和训练技术(例如自监督学习、预训练)在临床相关的医疗任务上的表现。简言之,就是测试最新一些通用人工智能方法在医疗任务上的表现。
BenchMD包括19个公开数据集,7种医疗数据模态,1维传感器数据、2维图片、3维扫描数据。
结果表明,没有一种与模态无关的技术在所有模态上都能实现强大的性能,基准模型有充足的改进空间。
引言 #
背景:Transformers模型和自监督学习(SSL)对标签数据需求小、能灵活运用到多种模态的数据。
问题:衡量这些进展在领域内的效果需要制定具有广度和深度的评测,以捕捉应用和模式的多样性,并通过让专家参与评测过程来确保外部有效性。
当前医疗AI领域应用时针对具体问题,通过试验选择不同的架构以及自监督学习方法,期望发展一种灵活、与模态无关无需定制化就能应用到各类问题的方法。
解决:BenchMD针对每种模态构建标准化、临床有效的评估方法,并通过专家验证;同时探索了基准数据标签不足情况和数据偏移情况下的表现;
同时,为了让BenchMD更加容易使用:
- 易用性:新架构和任务即插即用
- 易复现:全部使用公开数据集
结果显示医疗AI领域通用、泛化性强方法仍需继续研究。
相关工作 #
- 模态无关的技术:SSL
- 掩码建模
- 对比学习
- 模态无关的医学人工智能
- 在医学图像上自监督MAE比ImageNet上预训练要好
- 医学影像有无监督预训练加上监督学习表现好
- 现有多种模态的基准测试
模态和数据集 #
整理了一系列高影响模态数据以及精心挑选的数据源和目标数据集,用于评估分布外 (OOD) 性能。
12-lead ECGs #
利用5秒采样频率为500Hz的12导心电数据进行7分类:正常、传导障碍、心肌肥厚、心肌梗死、缺血性ST-T改变、心房颤动/心房扑动及其他。
数据包括:
- PTB-XL (18k) 1989-1996
- Chapman-Shaoxing (10k) 2020
- Georgia 12-Lead ECG Challenge (10k) 2020
- China Physiological Signal Challenge (6.8k) 2018
EEG #
30秒单导EEG睡眠分期任务。使用AASM睡眠分期标准:觉醒、快速眼动、非快速眼动I期、非快速眼动2期、非快速眼动3期。
数据包括:
- SHHS (5.8k) 1995-1998
- includes 5,804 adults aged 40 and older
- BioLINCC: Sleep Heart Health Study (SHHS)
- ISRUC-Sleep(0.1k)2009-2013
- collected from subjects in hospital whose ages range from 20 years old to 85 years old, with an average age of 51
- ISRUC-SLEEP Dataset | A comprehensive public dataset for sleep researchers
Chest X-Rays #
使用2D灰度胸片进行单标签分类任务,包括肺不张、心脏扩大、实变、水肿和胸腔积液。
数据包括:
- MIMIC-CXR (227k) 2011-2016
- a large publicly available dataset of chest radiographs in DICOM format with free-text radiology reports.
- MIMIC-CXR Database v2.0.0
- CheXpert (65k) 2002-2017
- a large public dataset for chest radiograph interpretation, consisting of 224,316 chest radiographs of 65,240 patients.
- [CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison](https://stanfordmlgroup.github.io/competitions/chexpert/
- VinDr-CXR (18k) 2018-2020
- The published dataset consists of 18,000 postero-anterior (PA) view CXR scans that come with both the localization of critical findings and the classification of common thoracic diseases.
- VinDr-CXR: An open dataset and benchmarks for disease classification and abnormality localization on chest radiographs | VinDr
Mammograms #
乳腺X光检查包括患者左右乳房不同视图的2D灰度图像从1-5类BI-RADS分级。
数据包括:
- VinDr-Mammo (5k) 2018-2020
- a large-scale benchmark dataset of full-field digital mammography, called VinDr-Mammo
- VinDr-Mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography | VinDr
- CBIS-DDSM (2.6k)1988-1999
- The DDSM is a database of 2,620 scanned film mammography studies. It contains normal, benign, and malignant cases with verified pathology information.
- Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) - The Cancer Imaging Archive (TCIA) Public Access - Cancer Imaging Archive Wiki
Dermoscopic #
基于2D RGB皮肤图像进行单标签分类,共5类:AKIEC“(包括光化性角化病、上皮内癌和鳞状细胞癌,因为所有这些都是鳞状细胞癌的连续体)、”BCC“(基底细胞癌)、”MEL“(黑色素瘤)、”NEV“(痣)和”其他疾病“(皮肤纤维瘤等)。
数据包括:
- BCN20000(19k)2010-2016
- HAM10000(10k)
- PAD-UFES-20(1.37k)2018-2019
- a nonprofit program that provides free skin lesion treatment, in particular, to low-income people who cannot afford private treatment.
- paper: [2007.00478] PAD-UFES-20: a skin lesion dataset composed of patient data and clinical images collected from smartphones
- data: PAD-UFES-20: a skin lesion dataset composed of patient data and clinical images collected from smartphones - Mendeley Data
Fundus Images #
基于2D RGB眼底图像预测糖尿病视网膜病变严重程度,基于ICDR分级共5类
数据包括:
- Messidor-2(0.5k)2004-2010
- a collection of Diabetic Retinopathy (DR) examinations, each consisting of two macula-centered eye fundus images (one per eye)
- Messidor-2 - ADCIS
- APTOS 2019(3.6k)2019
- 3662 samples collected from many participants of rural India
- APTOS 2019 Blindness Detection | Kaggle
- Jinchi Medical University dataset(2.7k)2011-2015
Low Dose Computer Tomography Scans(LDCT) #
基于3D CT影像进行判断结节大小
数据包括:
- LIDC-IDRI(1.0k)2010
- LNDb(294)2016-2018
实验 #
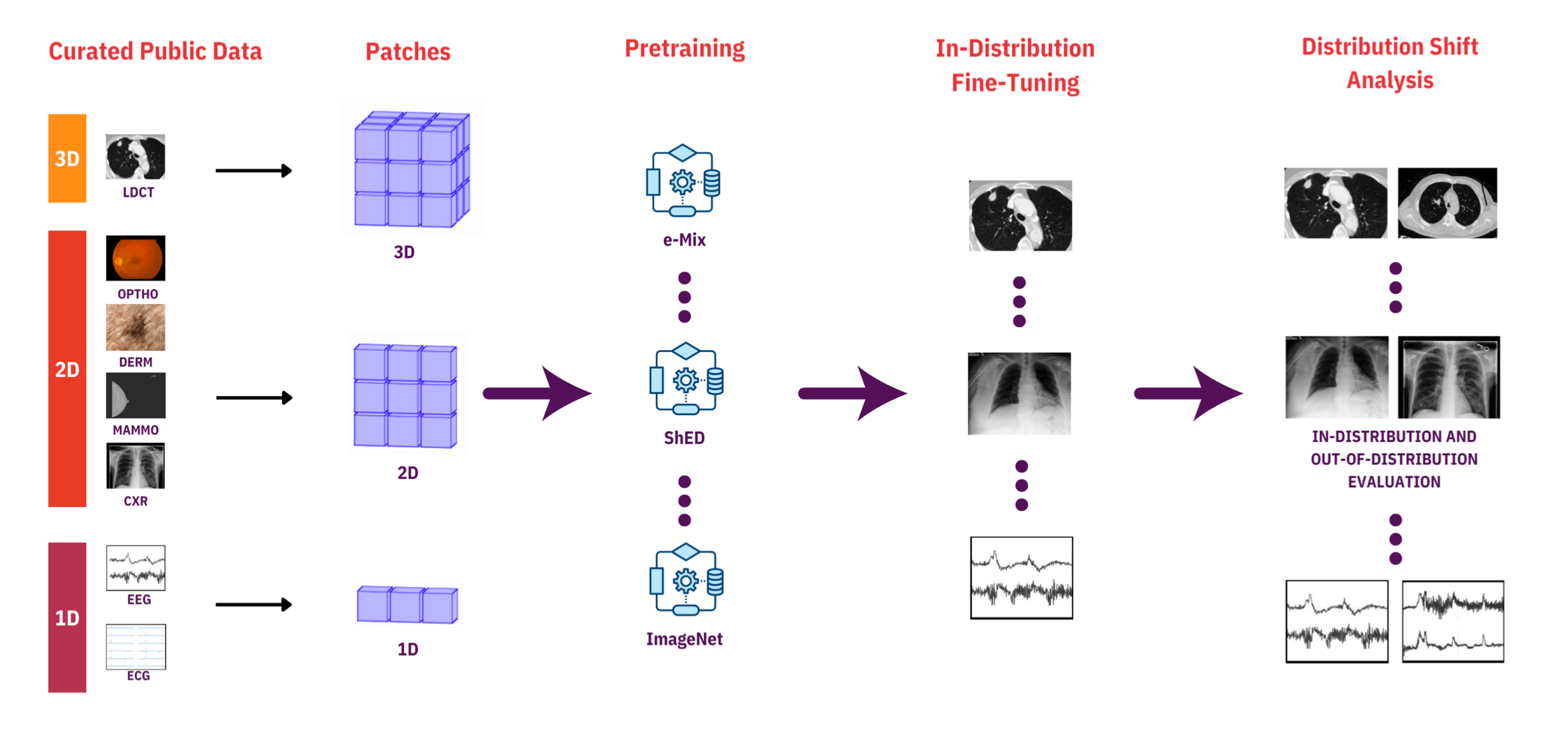
对5种技术进行评估:3种SSL算法、ImageNet预训练、从头训练,然后使用多种迁移学习方法测试在分布外(OOD)数据中性能。
网络架构 #
分别使用1D、2D和3D的embedding模块处理原始数据形成256维度的嵌入空间,不同输入维度的信息能混合。编码器使用的是标准的ViT架构。
预训练 #
三种自监督方法
- Contrastive embedding-Mixup(e-Mix)
- 使用一定的比例系数对原始输入嵌入加权并相加,训练编码器为混合输入产生一个向量,该向量与原始输入经过混合因子加权相加尽量相近
- Shuffled embedding prediction(ShED)
- 打乱一部分输入嵌入,使用带分类器的编码器来预测被扰动过的嵌入
- MAE
- 对输入嵌入表达进行75%的掩码,训练模型重建输入对嵌入表达
迁移学习以及分布外评价 #
固定模型骨架利用分布内数据训练一个线性分类器进行微调。然后在分布外数据集中进行zero-shot评估。微调数据集的选取,单标签任务选取,多标签任务选取。
结果 #
- 各类自监督方法在各模态数据上表现不一致,需要探索在各模态数据中表现更加一致的SSL算法
- SSL有时优于预训练方法,有时预训练也可以和SSL表现相当。未来需要探索在其他数据集例如imagenet中进行预训练,然后在医疗数据集中进行SSL,即预训练与自监督结合。
- 微调过程中标化数据量影响模型性能,越多越好,但也要防止过拟合的情况发生。
- 分布内与分布外数据模型性能比较表明需要探索提升模型可泛化性能的正则化技术
思考 #
自监督技术和预训练技术在NLP和CV领域应用广泛,如何应用到各类医疗数据中,是不是在所有种类的医疗数据中表现都比不使用要好,本文通过构建各类基准模型尝试回答该问题,相比于NLP和CV领域,医疗领域数据种类繁多导致当前没有一种统一的方法适用于所有的情形,需要进一步研究判断对各种类的数据适合使用的方法,以及预训练与自监督技术联合使用的方法。
Wantlin, K. et al. BenchMD: A Benchmark for Modality-Agnostic Learning on Medical Images and Sensors. Preprint at https://doi.org/10.48550/arXiv.2304.08486 (2023).