PyTorch深度学习(2)
·4 mins
Table of Contents
Deep Learning = Learning Hierarchical Representations
深度学习即学习层次的表征。
1. 卷积神经网络 #
1.1 神经网络可视化(Visualization of neural networks) #
神经网络每一层的操作有点像将空间某些区域进行折叠
1.2 卷积神经网络的起源(Convolutional Neural Network;CNN) #
受到Fukushima在视觉皮层建模方面的启发,使用简单/复杂的细胞层次结构,结合有监督的训练和反向传播,由Yann LeCun教授于88-89年在多伦多大学开发了第一个CNN。
Fukushima的工作具体是什么呢?
手写数字识别。首次提出应用多层简单或者复杂的细胞结构建模,特征:手工加无监督聚类学习。无反向传播。
1.3 卷积神经网络分解 #
通用的CNN架构能被分解为以下几个基本结构。
- 标准化(Normalisation):对比度标准化等
- 滤波器组(Filter banks):边缘检测等
- 非线性化(Non-linearities):稀疏化、ReLU等
- 池化(pooling):最大池化(max pooling)等
2. 自然信号数据(Natural Signals) #
2.1 自然信号数据特性 #
- 周期性:在时域很多模式都会重复出现
- 局部性:相邻的点较相远的点来说更具关联性
- 合成性:复杂的事物可以由简单的事物组合而成。字母->单词->句子->文章
2.2 对应神经网络中的处理方法 #
- 周期性$\rightarrow$参数共享
如果数据存在周期性,可以使用参数共享,即卷积核。 - 局部性$\rightarrow$稀疏
如果数据存在局部性,那么每个神经元只需要与前几个神经元连接 - 合成性$\rightarrow$多层
即神经网络中多层网络合成最终的结果
3. Pytorch实现Mnist手写字识别 #
# load package and data
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 神经网络模型偏爱标准化数据,原因是均值为0方差为1的数据在sigmoid、tanh经过激活函数后求导得到的导数很大,
# 反之原始数据不仅分布不均(噪声大)而且数值通常都很大(本例中数值范围是0~255),激活函数后求导得到的导数
# 则接近与0,这也被称为梯度消失。
# 目录放自己下载好的mnist目录,没有下载将download=True,自己新建一个存放数据目录即可
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../LSTM_mnist/mnist', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
# mnist数据集均值0.1307,标准差0.3081
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../LSTM_mnist/mnist', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
# define model
class SimpleCNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
super(SimpleCNN, self).__init__()
self.n_feature = n_feature
# 关于nn.Conv2d()中参数的解释
# in_channels (int): Number of channels in the input image
# out_channels (int): Number of channels produced by the convolution
# kernel_size (int or tuple): Size of the convolving kernel
# default stride=1, padding=0, dilation=1, groups=1
# [groupsc参数详解](https://www.jianshu.com/p/20ba3d8f283c)
# [图解卷积神经网络中stride, padding等操作可视化](https://github.com/vdumoulin/conv_arithmetic)
# input: (N, C_in, H_in, W_in)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = self.conv1(x) # Mnist数据原始大小(28*28)28-5+1 = 24 (24*24*n_feature)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2) # (12*12*n_feature)
x = self.conv2(x) # 12-5+1 = 8 (8*8*n_feature)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2) # (4*4*n_feature)这里解释了上面全连接时为啥是4*4
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
# hyper parameters
epochs = 1
input_size = 28*28
output_size = 10
n_features = 6
lr = 0.01
model = SimpleCNN(input_size, n_features, output_size)
model.to(device)
# optimizer
optimizer = optim.SGD(model.parameters(), lr, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model)))
# model train
for epoch in range(epochs):
model.train()
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = F.nll_loss(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print('Train Epoch [{}/{}], [{}/{} ({:.0f}%)], Loss: {:.4f}'.format(
epoch+1, epochs, i*len(data), len(train_loader.dataset),
100*i/len(train_loader), loss.item()))
# model eval
model.eval()
test_loss = 0
correct = 0
accuracy_list = []
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
accuracy_list.append(accuracy)
print('\nTest set Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset), accuracy))
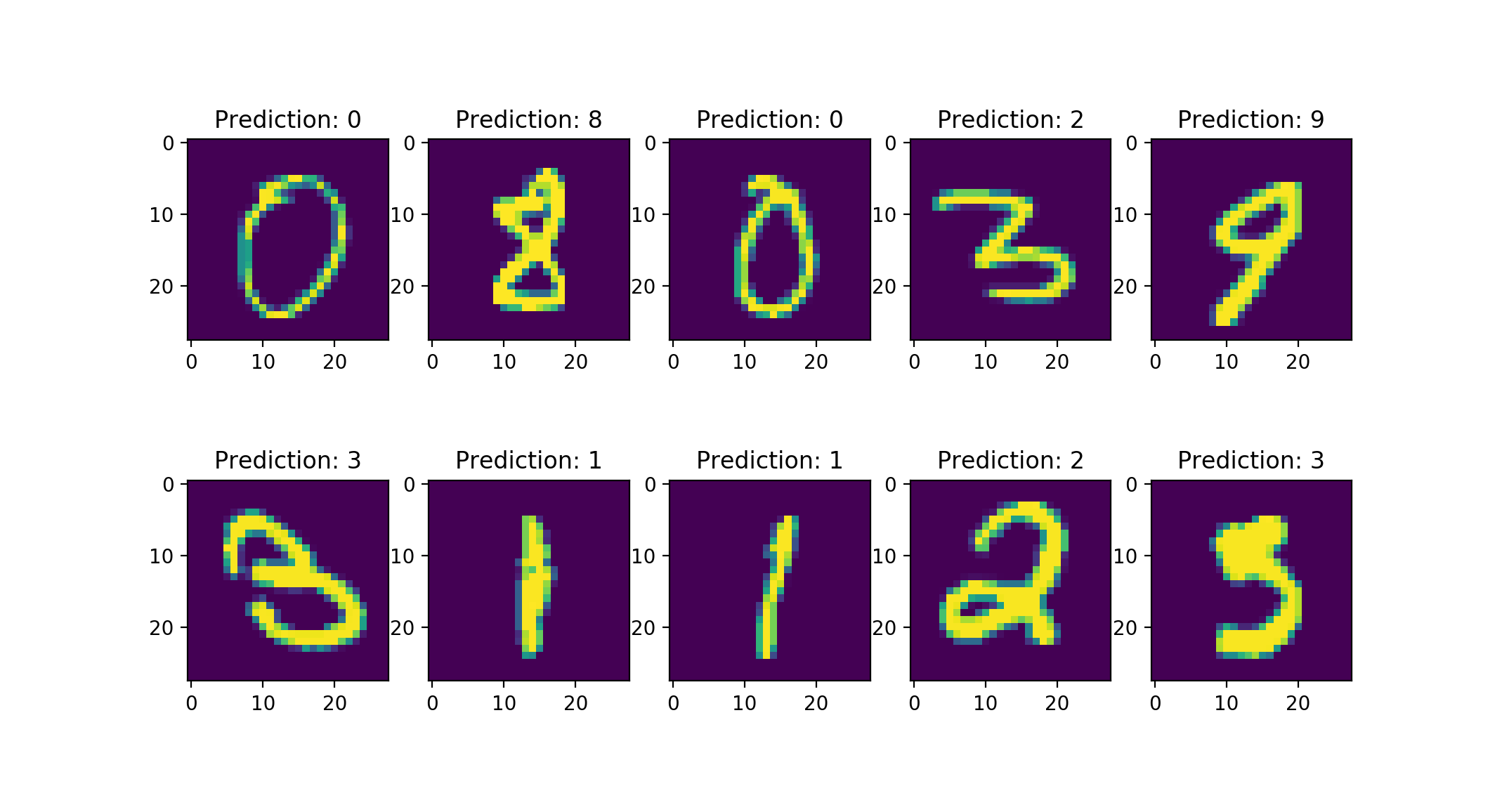
# 几个预测的实例可视化
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(data[i][0])
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.show()
4. 补充 #
- 可以做一个有趣的实验即打乱图片中的像素后CNN识别正确率下降,而全连接网络则不会,即与最开始提到的三个特性以及对于神经网络采取的假设是吻合的。
- 参考2中是对卷积神经网络全面的介绍,包括CNN中常用那些层,以及常用的模型和参数多少计算。