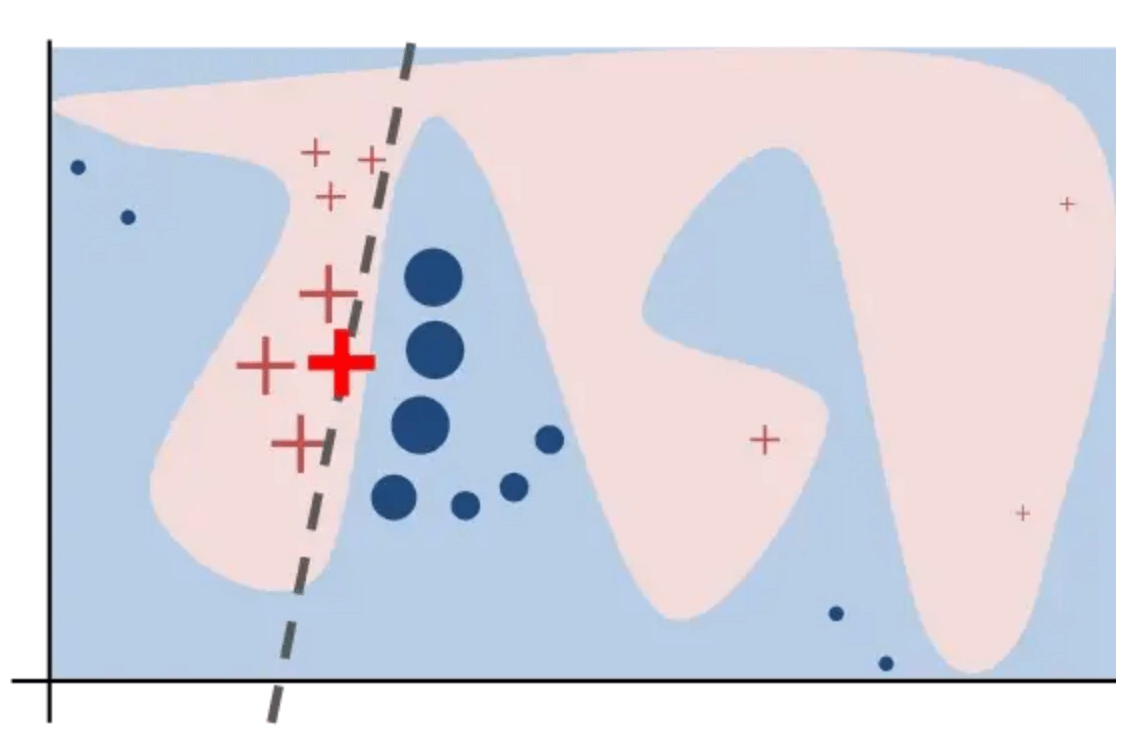
LIME2(Local interpretable model-agnostic explanations)(why should I trust you: Explaining the predictions of any classifier)通过生成的包含需要解释点周围的扰动数据和基于黑箱模型预测结果的数据集,训练一个可以解释的模型,比如逻辑回归、决策树,这个可解释模型需要在解释点周围达到较好的效果。
$$\xi = \mathop{\arg\min}\limits_{g\in G}L(f,g,\pi_x) + \Omega(g)$$
f为需解释模型
g为可能的解释模型
$\pi_x$为定义实例周围多大范围
算法过程:
选择需要解释感兴趣的实例
对其进行扰动,并得到黑箱模型对应结果产生新数据集
根据与实例的接近程度,对新数据集进行赋予权重
基于新数据集和上述损失函数求解可解释模型
解释预测值Figure 3: Toy example to present intuition for LIME
从线性模型中返回Shapley values
SHAP核为(推导过程见2补充材料):
$$\pi_{x’}(z’)= \frac{(M-1)}{(M choose |z’|)|z’|(M-|z’|)}$$
$$L(f,g, \pi_{x’})=\sum_{z’\in Z}[f(h_x^{-1}(z’))-g(z’)]^2\pi_{x’}(z’)$$
x’为简化输入,$x=h_x(x’)$, $z’ \subseteq x’$
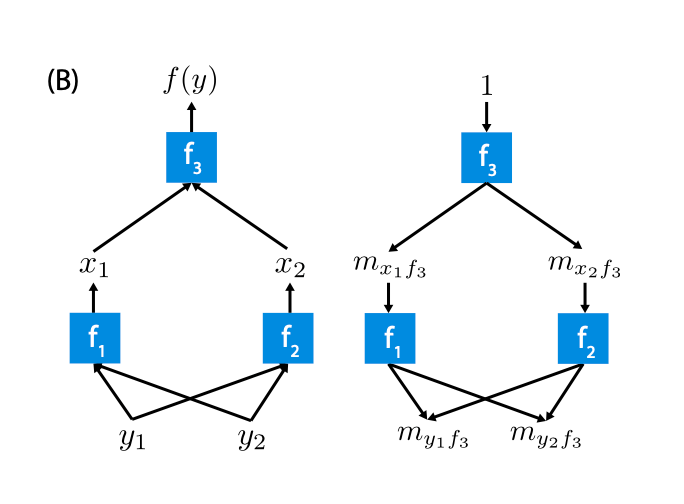
其中第二步:The function h maps 1’s to the corresponding value from the instance x that we want to explain. For tabular data, it maps 0’s to the values of another instance that we sample from the data. This means that we equate “feature value is absent” with “feature value is replaced by random feature value from data”.
choosing a good reference would rely on domain-specific knowledge, and in some cases it may be best to compute DeepLIFT scores against multiple different references
the Shapely values measure the average marginal effect of including an input over all possible orderings in which inputs can be included. If we define “including” an input as setting it to its actual value instead of its reference value, DeepLIFT can be thought of as a fast approximation of the Shapely values8
Though a variety of methods exist for estimating SHAP values, we implemented a modified version of the DeepLIFT algorithm, which computes SHAP by estimating differences in model activations during backpropagation relative to a standard reference.figure from ref[3]
Ribeiro, M. T., Singh, S. & Guestrin, C. ‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 1135–1144 (2016) doi:10.1145/2939672.2939778. ↩︎
Shrikumar, A., Greenside, P., Shcherbina, A. & Kundaje, A. Not Just a Black Box: Learning Important Features Through Propagating Activation Differences. Preprint at https://doi.org/10.48550/arXiv.1605.01713 (2017). ↩︎
Shrikumar, A., Greenside, P. & Kundaje, A. Learning Important Features Through Propagating Activation Differences. Preprint at http://arxiv.org/abs/1704.02685 (2019). ↩︎