公开重症监护数据库MIMIC-IV介绍
Table of Contents
背景 #
- 本文1首先介绍mimic项目的由来,医院数据归档系统都不是为研究设计的,难以访问以及查询;
- MIMIC从0-4发展简介;
- 其他数据库简介
- eICU-CRD,美国多中心200859例ICU记录
- AmsterdamUMCdb,荷兰单医学中心20109例患者23106次入院记录
- HiRIDData details,瑞士34000入院患者高分辨率数据(每两分钟一个数据点,712中常规手机生理数据)
- HiRID has a higher time resolution than other published datasets, most importantly for bedside monitoring with most parameters recorded every 2 minutes
- 去隐私化方法可以借鉴
- PIC,中国12881例患者13941次儿科ICU记录
- 问题,当前数据库都只是单模态的数据或各有特点,且临床实践发展变化快,数据库需要不断更新完善;
- MIMIC-IV是当代的综合多模态数据库
方法 #
mimic-iv数据库是怎么建的?
- 获取、转化、去隐私化
获取 #
BIDMC医院常规的临床数据存储在microsoft SQL中,通过VPN转移到MIT服务器的PostgreSQL,补充数据如ICD、患者死亡信息等外部导入到PostgreSQL
- 队列:2008-2019,18岁以上
- 床旁信息来自于MetaVision,医院EHR会通过HL7推信息到MetaVision
- 外部数据主要说明DRGs和ICD是如何处理以及死亡信息如何处理
- DRGs和ICD由于数据库跨度时间长以及不同版本,在数据库中把这些都导入了
- 死亡信息通过与马萨诸塞州生命记录和统计登记处进行匹配,而非社保档案
转化 #
转化有两条原则
- 与MIMIC-III保持兼容
- 尽量减少处理过程让公开数据与临床实践数据保持一致
数据被分为三个组:hosp、icu和note
- hosp:admission/discharge/transfer(ADT),实验室检查结果,微生物培养,处方,管理数据
- icu:患者出入量、输液、操作、记录到的观测值等
- note:出院总结和放射学报告,也创建了相对应的自由文本结构化表“实体-属性-值”
去隐私化 #
- 遵从The Health Insurance Portability and Accountability Act(HIPAA)条款规定了18项标识符,包括姓名、地址、年龄等需要去掉
- 日期移动,但时间点间距保留
- 结合了两个公开的算法23从自由文本中移除个人健康信息(PHI)
- 两个算法都没捕捉到的,从数据库中移除?这个没写具体怎么做
数据记录结果 #
这一部分类似传统论文的结果,详细介绍了hosp、icu、note模块里面的数据情况,对各表进行介绍
Hosp #
首先介绍模块里主要键值以及表之间连接关系,与MIMIC-III一致
患者基本信息:patients、admissions和transfers表
- 患者时间信息,anchor_year、anchor_age、anchor_year_group这几个重要项
- anchor_year锚定年份,由于时间都是去隐私化的平移过的,这里可以看作平移之后的参考年份
- anchor_year_group是真实年份的区间
- 患者死亡信息最多到患者出院1年为止
管理信息:services、poe、poe_detail表
- services 患者住院期间所受到的医疗服务
- poe 医嘱录入系统:治疗和操作
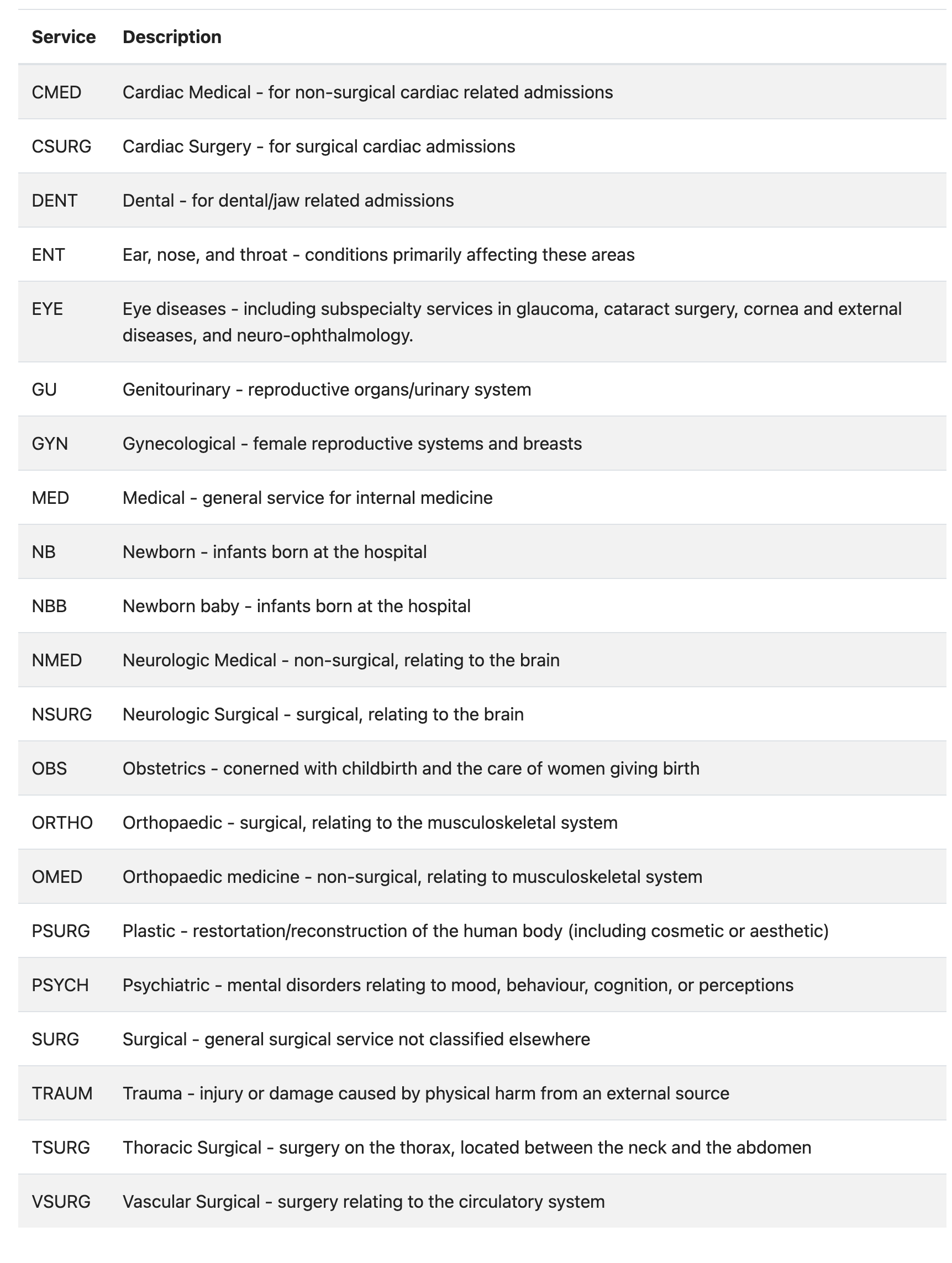
计费信息:diagnoses_icd、procedures_icd、drgcodes、hcpcsevents
检查结果:microbiologyevents、labevents
药物信息:prescriptions、pharmacy、emar、emar_detail
- 处方、药房信息;
- 2016年部署electronic Medicine Administration Record,eMAR;
- 看起来关系比较复杂使用得结合实例
ICU #
chartevents, d_items, datetimeevents, icustays, inputevents, outputevents, and procedureevents表
Note #
出院总结:
- 主诉、现病史、既往病史、简要病程、体格检查和出院诊断
放射学报告:
- x射线、CT、MRI、超声
技术验证结果 #
- 完整性检查
- 数据库自身是完备的,不会出现某个患者的信息只出现一张表其他表都找不到的情况
- 一致性检查
- 数据结果与一些常识一致
- 去隐私化检查
使用笔记 #
- 如何获取
- 参加课程
- 签署data use agreement, DUA
- 代码库以及模版
思考 #
- MIMIC数据库一步一步发展已经来到了第四版,很好的体现了科学研究的可持续发展。
- 与MIMIC-III论文写法不同,mimic-iv对数据库构建过程写的更加详细,可操作性更高,而mimic-iii由于没有很好的把这个过程结构化抽象分成几步显得构建细节不足,而mimic-iii论文表格比较丰富,对数据库进行了一些粗粒度的介绍,mimic-iv论文没有。个人认为iv这篇论文写的更好一点。
- 伴随着数据类型越来越多、数据库越来越多,数据分析人员也需要掌握更多类型数据预处理方法。面对文本、图像、波形的多模态数据分析或者在不完备数据情况下模型的不确定性成为两个相对应的研究方向。
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data 10, 1 (2023). ↩︎
Neamatullah, I. et al. Automated de-identification of free-text medical records. BMC medical informatics and decision making 8,1–17 (2008). ↩︎
Johnson, A. E. W., Bulgarelli, L. & Pollard, T. J. Deidentification of free-text medical records using pre-trained bidirectional transformers. In Proceedings of the ACM Conference on Health, Inference, and Learning, 214–221 (2020). ↩︎