生存分析(一)
Table of Contents
简介 #
生存分析是将观察的结局和出现结局所经历的时间结合起来进行分析的一系列统计方法,常用于研究影响因素与生存时间和结局的关系,预测不同因素水平个体生存预测。
因为跟时间相关,所以要定义要事件起点,以及事件终点。生存时间T也可以根据事件起终点计算出来。
由于有些事件无法被观测或者没有观察到,导致生存时间无法被记录的情况称为删失。其中最为常见的情形称为右删失(right censoring,下图)
- 右删失:对这样的病人我们只知道其生存时间要大于从试验开始到删失发生的时间。有多种原因可以导致右删失情况的出现,其中包括:(1)病人在某时间点上退出试验或失去随访信息;(2)病人在整个试验结束时事件还未发生;(3)病人由于毒性等原因停用被分派的药物或换用其它药物;(4)竞争风险事件的发生1。

- 左删失2:事件发生了,且发生时间在(0,t) ,但确切时间并不清楚。
- 区间删失: 事件发生在一个已知的具体时间段内,但是并不知道具体时间。
生存函数 #
生存函数$$S(t) = P(T>t)$$描述的是事件发生时间大于时间点t的概率,理论上T是连续变量,那么生存函数是一个连续的递减函数,然而实际实验中T都是有限时间点的,所以连续曲线变成离散的。“若想用光滑曲线来连接就需要对随机变量T的分布做出假设的参数拟合法,而曲线一般不宜正好经过所有的红点 (那样会导致过度拟合而使得统计模型没有多大效用) ;若用非参数的阶梯函数来连接,那么曲线简单而唯一确定!”这也是为什么k-m曲线这么重要的原因。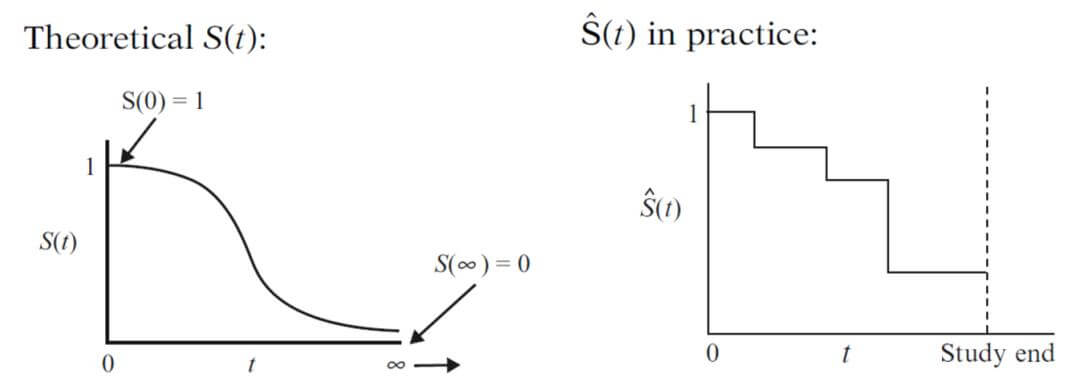
风险函数 #
风险函数的定义即在t时刻发生事件的概率。$$h(t)=P(T=t|T\ge t)$$生存函数是可以看到是从1到0递减的,而风险函数没有固定的单调性,可以是常数风险、可以随时间变化,比如上升、下降、先下降后上升。
假设生存时间T这个变量概率分布满足$f(t)$,累积分布$F(t)=P(T\le t)= \int_0^t f(t)dt$,可以看到生存函数$S(t)=1-F(t)$,两边求导数可得$$f(t)=-S’(t)$$ 那么在t时刻发生事件的风险用极限的观点来看即在$t -> t+\Delta t$ 这个区间内发生事件的数量除以在t时刻剩下的总人数$$h(t)=\lim_{\Delta t \to 0}\frac{F(t+\Delta t)-F(t)}{\Delta t*S(t)}=\frac{f(t)}{S(t)}=\frac{-S’(t)}{S(t)}$$ $$h(t)=\frac{-S’(t)}{S(t)}=-\frac{\partial}{\partial y}log[S(t)]\tag1$$
$$S(t)=exp[-\int_0^th(t)dt]\tag2$$ 式1后面一个等式右边求偏微分等于等式左边,两边积分即式2。以上为风险函数与生存函数之间的关系3
Kaplan-Meier生存曲线 #
K-M曲线是非参数估计生存函数的一种方法。
如何绘制K-M生存曲线? 临床原始资料一般如下:
| 患者 | 生存时间 | 发生事件与否 | 删失与否 |
|---|---|---|---|
| a | 10 | 0 | r |
| b | 28 | 1 | |
| c | 30 | 1 | |
| d | 2 | 1 | |
| e | 7 | 0 | r |
| 假设是来分析患者生存分析,定义结局是死亡,最长实验观察时间是90天, |
首先是判断删失数据,假设a和e患者分别出院,观察不到死亡结局,那么以上两个患者是删失数据。
将资料整理成生存概率随时间变化表格
| 患者 | 生存时间 | 存活患者数n | 死亡人数d | 当前存活概率(n-d)/n | 生存概率 |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| d | 2 | 5 | 1 | 4/5 | 4/5 |
| e | 7+ | ||||
| a | 10+ | ||||
| b | 28 | 2 | 1 | 1/2 | ${4/5}*{1/2}=2/5$ |
| c | 30 | 1 | 1 | 0 | 0 |
将上表生存时间以及生存概率可视化即可得到k-m曲线。
以上介绍了生存分析的基本原理以及非参数生存分析K-M曲线是如何来的,有空介绍半参以及参数化的生存分析方法。
怎么理解生存分析的风险函数? - 数据的小米虫的回答 - 知乎 https://www.zhihu.com/question/343779367/answer/2439383246 ↩︎
怎么理解生存分析的风险函数? - 郭老师医学统计的回答 - 知乎 https://www.zhihu.com/question/343779367/answer/1493205766 ↩︎